Natural language processing (NLP) is a field within artificial intelligence that enables computers to interpret and understand human language. Using machine learning and AI, NLP tools analyze text or speech to identify context, meaning, and patterns, allowing computers to process language much like humans do. One of the key benefits of NLP is that it enables users to engage with computer systems through regular, conversational language—meaning no advanced computing or coding knowledge is needed. It’s the foundation of generative AI systems like ChatGPT, Google Gemini, and Claude, powering their ability to sift through vast amounts of data to extract valuable insights.
We evaluated eight top-rated NLP tools to see how they compared on features, pros and cons, and pricing. Here are our picks for the best NLP software for your business needs:
- Hugging Face Transformers: Best for Pre-trained Models and Customization
- spaCy: Best for Fast, Production-Ready Text Processing
- IBM Watson: Best for Comprehensive Enterprise Text Analysis
- Natural Language Toolkit: Best for Educators and Researchers
- MonkeyLearn: Best for Ease of Use in Text Analysis
- Amazon Comprehend: Best for Seamless Integration with AWS
- Stanford CoreNLP: Best for Best for In-Depth Linguistic Analysis
- Google Cloud Natural Language API: Best for Scalable Text Insights
Featured Partners: AI Software

Top Natural Language Processing Software Comparison
| Best For | Language Support | Open Source | License | Cost | |
|---|---|---|---|---|---|
| Hugging Face Transformers | Pre-Trained Models and Customizations | Python, JavaScript (via API) | Yes | Apache 2.0 | Free Paid API access available |
| spaCy | Fast, Production-Ready Text Processing | Python | Yes | MIT | Free |
| IBM Watson | Comprehensive Enterprise Text Analysis | Various | No | Proprietary | Starts at $0.003 per item |
| Natural Language Toolkit | Educators and Researchers | Python | Yes | Apache 2.0 | Free |
| MonkeyLearn | Ease of Use in Text Analysis | Various (APIs in Python, Java, Ruby, etc.) | No | Proprietary | Starts at $299/month |
| Amazon Comprehend | Seamless Integration with AWS | Various) | No | Proprietary | Pay-per-use (pricing varies) |
| Stanford CoreNLP | Best for Best for In-Depth Linguistic Analysis | Java | Yes | GPL | Free |
| Google Cloud Natural Language API | Best for Scalable Text Insights | Various | No | Proprietary | Pay-per-use (pricing varies) |
TABLE OF CONTENTS
Hugging Face Transformers
Best for Pre-Trained Models and Customizations
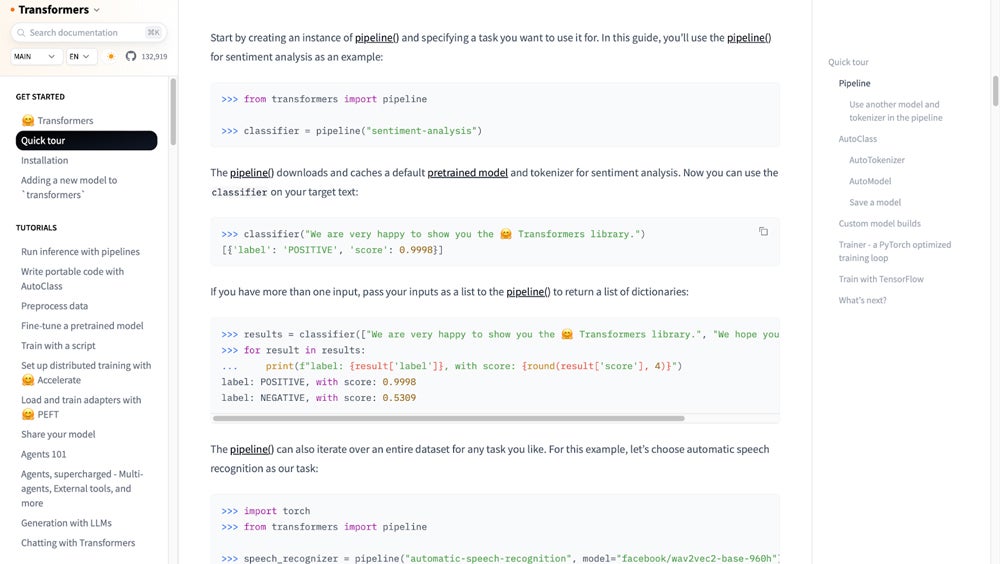
Hugging Face Transformers has established itself as a key player in the natural language processing field, offering an extensive library of pre-trained models that cater to a range of tasks, from text generation to question-answering. Built primarily for Python, the library simplifies working with state-of-the-art models like BERT, GPT-2, RoBERTa, and T5, among others. Developers can access these models through the Hugging Face API and then integrate them into applications like chatbots, translation services, virtual assistants, and voice recognition systems.
Hugging Face is known for its user-friendliness, allowing both beginners and advanced users to use powerful AI models without having to deep-dive into the weeds of machine learning. Its extensive model hub provides access to thousands of community-contributed models, including those fine-tuned for specific use cases like sentiment analysis and question answering. Hugging Face also supports integration with the popular TensorFlow and PyTorch frameworks, bringing even more flexibility to building and deploying custom models.
Why We Picked Hugging Face Transformers
We picked Hugging Face Transformers for its extensive library of pre-trained models and its flexibility in customization. Its user-friendly interface and support for multiple deep learning frameworks make it ideal for developers looking to implement robust NLP models quickly.
Pros and Cons
| Pros | Cons |
|---|---|
| Extensive model library | High resource requirement for larger models |
| Cross-framework compatibility | Learning curve for customization |
| Active community and lots of documentation | Limited free API access |
Pricing
- Open-source and free to use under the Apache 2.0 license
- Access to hosted inference API and advanced features is subscription-based; learn more on the Hugging Face website
Features
- Provides access to pre-trained models like GPT-2, BERT, and T5
- Supports custom model training and fine-tuning for specialized use cases
- Compatible with multiple deep learning frameworks (TensorFlow, PyTorch)
- Extensive model hub for sharing and discovering models
Read eWeek’s guide to the best large language models to gain a deeper understanding of how LLMs can serve your business.
spaCy
Best for Fast, Production-Ready Text Processing
spaCy stands out for its speed and efficiency in text processing, making it a top choice for large-scale NLP tasks. Its pre-trained models can perform various NLP tasks out of the box, including tokenization, part-of-speech tagging, and dependency parsing. Its ease of use and streamlined API make it a popular choice among developers and researchers working on NLP projects.
spaCy supports more than 75 languages and offers 84 trained pipelines for 25 of these languages. It also integrates with modern transformer models like BERT, adding even more flexibility for advanced NLP applications.
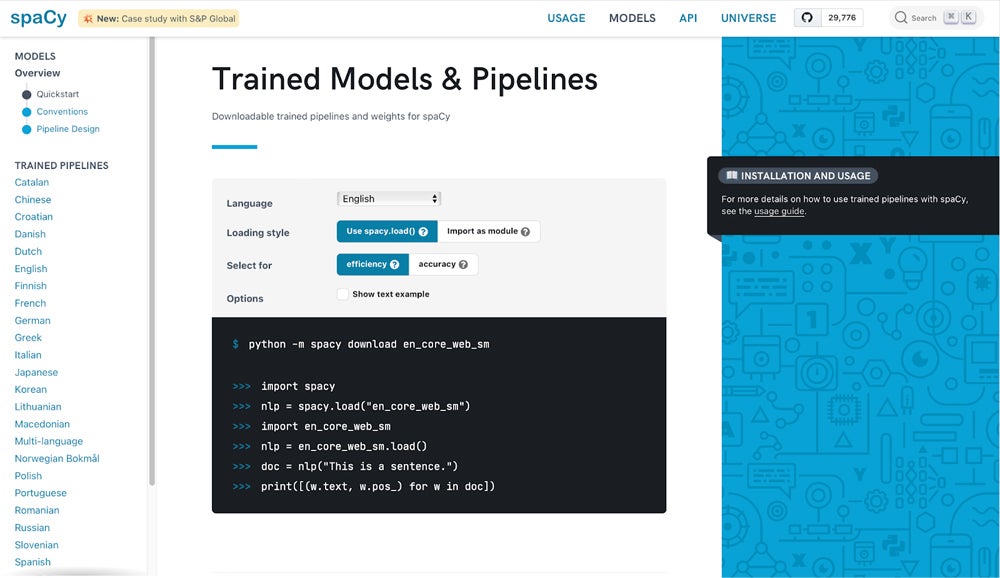
Why We Picked spaCy
We chose spaCy for its speed, efficiency, and comprehensive built-in tools, which make it ideal for large-scale NLP tasks. Its straightforward API, support for over 75 languages, and integration with modern transformer models make it a popular choice among researchers and developers alike.
Pros and Cons
| Pros | Cons |
|---|---|
| Straightforward and user-friendly API | Limited flexibility for customization and fine-tuning |
| Popular in the NLP community due to speed and efficiency | Requires some programming knowledge to customize models |
| Comprehensive built-in language tools | Limited support for deep language generation tasks |
Pricing
- Free, open-source library for personal and commercial use
Features
- Offers fast and accurate dependency parsing optimized for production environments
- Provides pre-trained language models for 25 languages
- Uses word vectors to identify word relationships and similarities
- Integrates custom models using TensorFlow or PyTorch
IBM Watson
Best for Comprehensive Enterprise Text Analysis
IBM Watson Natural Language Understanding (NLU) is a cloud-based platform that uses IBM’s proprietary artificial intelligence engine to analyze and interpret text data. It can extract critical information from unstructured text, such as entities, keywords, sentiment, and categories, and identify relationships between concepts for deeper context.
IBM Watson NLU is popular with large enterprises and research institutions and can be used in a variety of applications, from social media monitoring and customer feedback analysis to content categorization and market research. It’s well-suited for organizations that need advanced text analytics to enhance decision-making and gain a deeper understanding of customer behavior, market trends, and other important data insights.
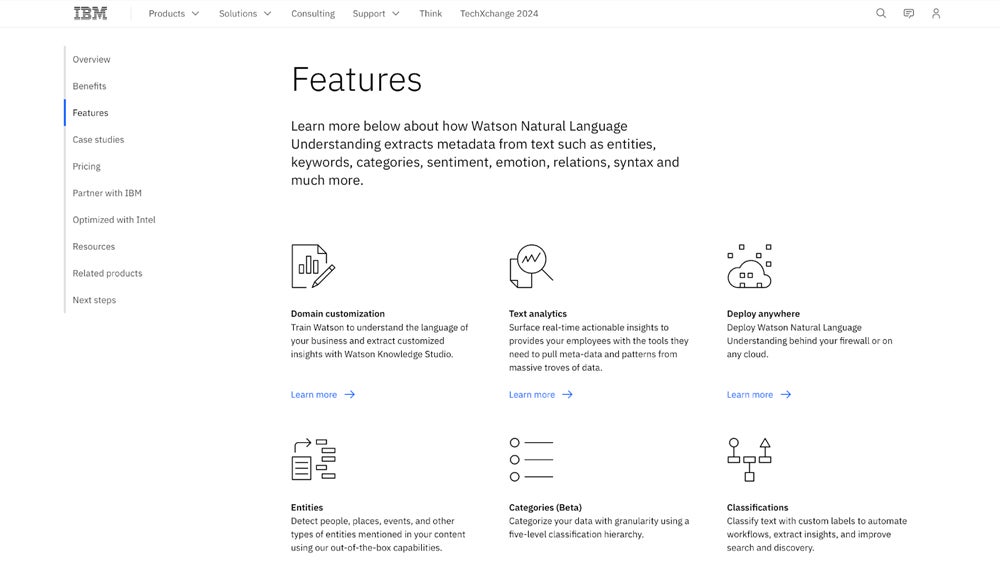
Why We Picked IBM Watson NLU
IBM Watson Natural Language Understanding stands out for its advanced text analytics capabilities, making it an excellent choice for enterprises needing deep, industry-specific data insights. Its numerous customization options and integration with IBM’s cloud services offer a powerful and scalable solution for text analysis.
Pros and Cons
| Pros | Cons |
|---|---|
| Simple and easy to use | Documentation could be better |
| Recognizes semantic roles | Sentiment analysis accuracy could be improved |
| Customizable models | High-volume use can be costly |
Pricing
- Lite: Free for 30,000 NLU items per month, along with one custom model
- Standard: $0.003 per 1–250,000 NLU items; $0.001 per 250,001–5,000,000 NLU items; $0.0002 per anything more than 5,000,000 NLU items
- Custom Entities and Relations Model: $800 per custom model, per month
- Custom Classification Model: $25 per custom classification model, per month
NLU items are units of text up to 10,000 characters analyzed for a single feature; total cost depends on the number of text units and features analyzed.
Features
- Extracts metadata from text, including language, concepts, and semantic roles
- Custom models with domain-specific training for specialized industries like finance and healthcare
- Integrates with IBM’s cloud services for scalable, real-time text analysis
- Supports entity linking to Knowledge Graphs for more comprehensive data insights
Natural Language Toolkit
Best for Educators and Researchers
The Natural Language Toolkit (NLTK) is a Python library designed for a broad range of NLP tasks. It includes modules for functions such as tokenization, part-of-speech tagging, parsing, and named entity recognition, providing a comprehensive toolkit for teaching, research, and building NLP applications. NLTK also provides access to more than 50 corpora (large collections of text) and lexicons for use in natural language processing projects.
NLTK is widely used in academia and industry for research and education, and has garnered major community support as a result. It offers a wide range of functionality for processing and analyzing text data, making it a valuable resource for those working on tasks such as sentiment analysis, text classification, machine translation, and more.

Why We Picked Natural Language Toolkit
NLTK is great for educators and researchers because it provides a broad range of NLP tools and access to a variety of text corpora. Its free and open-source format and its rich community support make it a top pick for academic and research-oriented NLP tasks.
Pros and Cons
| Pros | Cons |
|---|---|
| Excellent for academic research and NLP education | Not ideal for large-scale, production-level tasks |
| Rich community support and documentation | NLTK can be complex for beginners |
| Access to 50+ real-world text corpora and lexicons | Lacks modern deep learning tools |
Pricing
- Free, open-source, community-driven project
Features
- Available for Windows, Mac OS X, and Linux
- Provides tokenization and part-of-speech tagging tools for text analysis
- Integrates with WordNet for lexical database access
- Includes modules for named entity recognition, facilitating the identification of entities in text
MonkeyLearn
Best for Ease of Use in Text Analysis
MonkeyLearn is a machine learning platform that offers a wide range of text analysis tools for businesses and individuals. With MonkeyLearn, users can build, train, and deploy custom text analysis models to extract insights from their data. The platform provides pre-trained models for everyday text analysis tasks such as sentiment analysis, entity recognition, and keyword extraction, as well as the ability to create custom models tailored to specific needs.
MonkeyLearn’s APIs allow you to connect the tool to third-party apps like Zapier, Excel, and Zendesk, and also integrate it into your own platform. For example, you could use MonkeyLearn to analyze text data in Excel, automate text processing workflows through Zapier, or automatically categorize and prioritize support tickets in Zendesk.
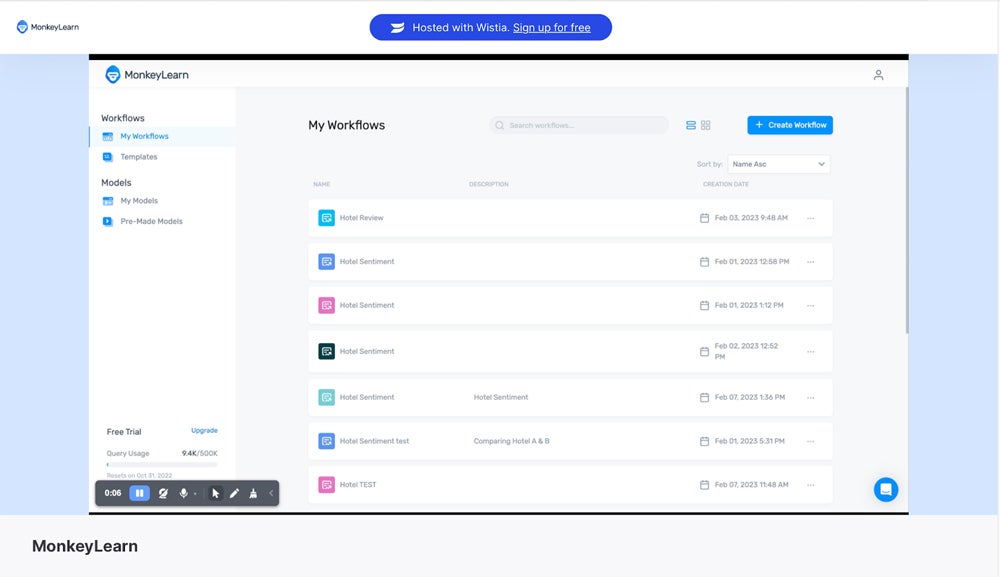
Why We Picked MonkeyLearn
MonkeyLearn offers ease of use with its drag-and-drop interface, pre-built models, and custom text analysis tools. Its ability to integrate with third-party apps like Excel and Zapier makes it a versatile and accessible option for text analysis. Likewise, its straightforward setup process allows users to quickly start extracting insights from their data.
Pros and Cons
| Pros | Cons |
|---|---|
| User-friendly interface with a modern design | Costly for individuals |
| Easy to implement | Advanced NLP functionalities may require a higher-tier plan |
| Customizable text analysis models | Not the most beginner-friendly option |
Pricing
- Does not advertise pricing
- Publicly available information shows that the MonkeyLearn API costs $299 per month, including 10,000 queries per month
- Contact the company for a custom quote
Features
- Builds custom text classifiers with an easy drag-and-drop interface
- Extracts key data using pre-built models for keywords, names, and sentiments
- Visualizes insights with MonkeyLearn Studio’s dashboards and word clouds
- Offers pre-trained models for customer satisfaction (CSAT) analysis
- Integrates with popular tools like Zapier, Google Sheets, and Zendesk via API
Amazon Comprehend
Best for Seamless Integration with AWS
Amazon Comprehend is a cloud-based NLP service powered by Amazon Web Services (AWS). It provides advanced features like custom entity recognition, targeted sentiment analysis, and Personally Identifiable Information (PII) detection, making it suitable for large-scale text processing tasks across industries like finance and customer service.
A central feature of Comprehend is its integration with other AWS services, allowing businesses to integrate text analysis into their existing workflows. Comprehend’s advanced models can handle vast amounts of unstructured data, making it ideal for large-scale business applications. It also supports custom entity recognition, enabling users to train it to detect specific terms relevant to their industry or business.
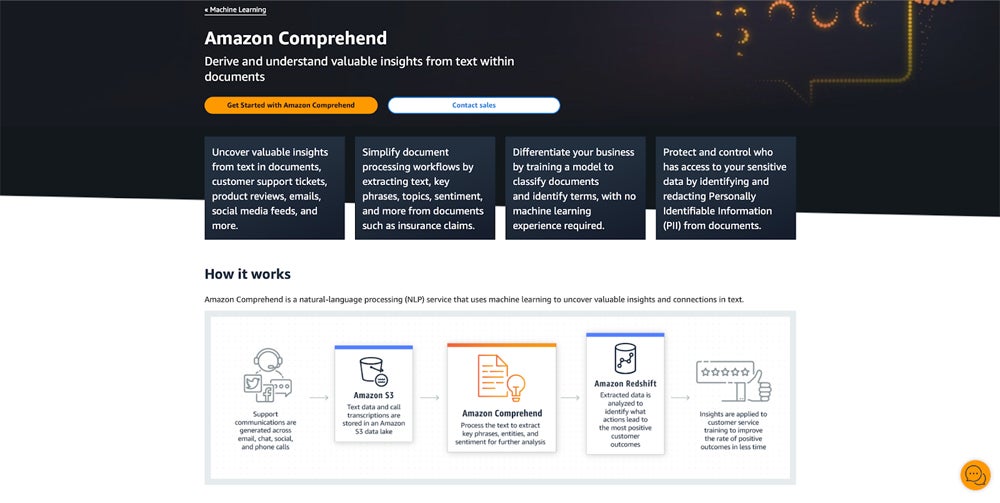
Why We Picked Amazon Comprehend
We picked Amazon Comprehend for its seamless integration with the power of AWS and its ability to handle high-volume, enterprise-scale text analysis. Its pay-as-you-go model and support for custom entity recognition make it suitable for businesses looking for robust and flexible NLP solutions.
Pros and Cons
| Pros | Cons |
|---|---|
| Tailors analysis to industry-specific terms | Requires familiarity with AWS for optimal use |
| Connects with Amazon S3, AWS Lambda, and other services | Less straightforward integration with non-AWS platforms |
| Handles high-volume text analysis with ease | Usage-based pricing can get expensive for large-scale projects |
Pricing
- Pay-as-you-go starting at $0.0001 per unit (100 characters)
- Custom models and PII detection come at additional cost
Features
- Trains custom entity recognition models to identify industry-specific terms
- Analyzes text for key phrases, entities, and sentiments using pre-built models
- Visualizes insights through AWS services like Amazon QuickSight
- Detects and redacts PII to help meet privacy regulations
- Integrates directly with AWS services like Amazon S3 and AWS Lambda for smooth workflows
Stanford CoreNLP
Best for In-Depth Linguistic Analysis
Stanford CoreNLP is written in Java and can analyze text in various programming languages, meaning it’s available to a wide array of developers. Indeed, it’s a popular choice for developers working on projects that involve complex processing and understanding natural language text.
CoreNLP provides a set of natural language analysis tools that can give detailed information about the text, such as part-of-speech tagging, named entity recognition, sentiment and text analysis, parsing, dependency and constituency parsing, and coreference. Its scalability and speed optimization stand out, making it suitable for complex tasks.
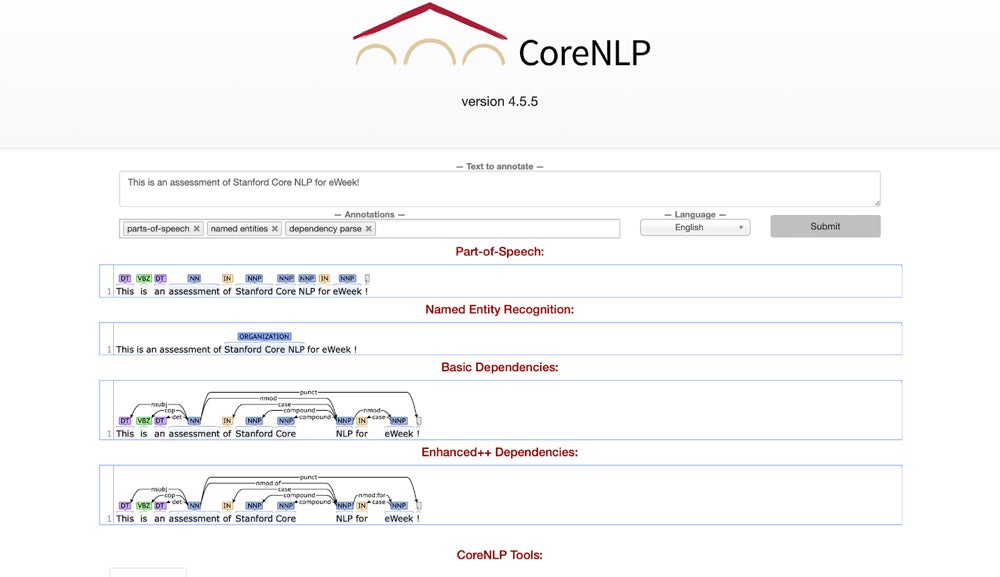
Why We Picked Stanford CoreNLP
We picked Stanford CoreNLP for its comprehensive suite of linguistic analysis tools, which allow for detailed text processing and multilingual support. As an open-source, Java-based library, it’s ideal for developers seeking to perform in-depth linguistic tasks without the need for deep learning models.
Pros and Cons
| Pros | Cons |
|---|---|
| Multilingual | Only supports eight languages |
| Fast and efficient | Restricted to Java |
| Extensible, with support for custom pipelines and annotations | Lacks built-in support for modern deep learning models |
Pricing
- Free, open-source tool
Features
- Provides a suite of NLP tools, including tokenization, part-of-speech tagging, named entity recognition, and parsing
- Offers multilingual support in eight languages, including models for English, Chinese, French, and German
- Includes sentiment analysis tools to assess the sentiment of sentences and documents
- Supports custom annotations, allowing users to add their own linguistic information to the text
Google Cloud Natural Language API
Best for Scalable Text Insights
Google Cloud Natural Language API is a service provided by Google that helps developers extract insights from unstructured text using machine learning algorithms. The API can analyze text for sentiment, entities, and syntax and categorize content into different categories. It also provides entity recognition, sentiment analysis, content classification, and syntax analysis tools.
Google Cloud Natural Language API is widely used by organizations leveraging Google’s cloud infrastructure for seamless integration with other Google services. It allows users to build custom ML models using AutoML Natural Language, a tool designed to create high-quality models without requiring extensive knowledge in machine learning, using Google’s NLP technology.
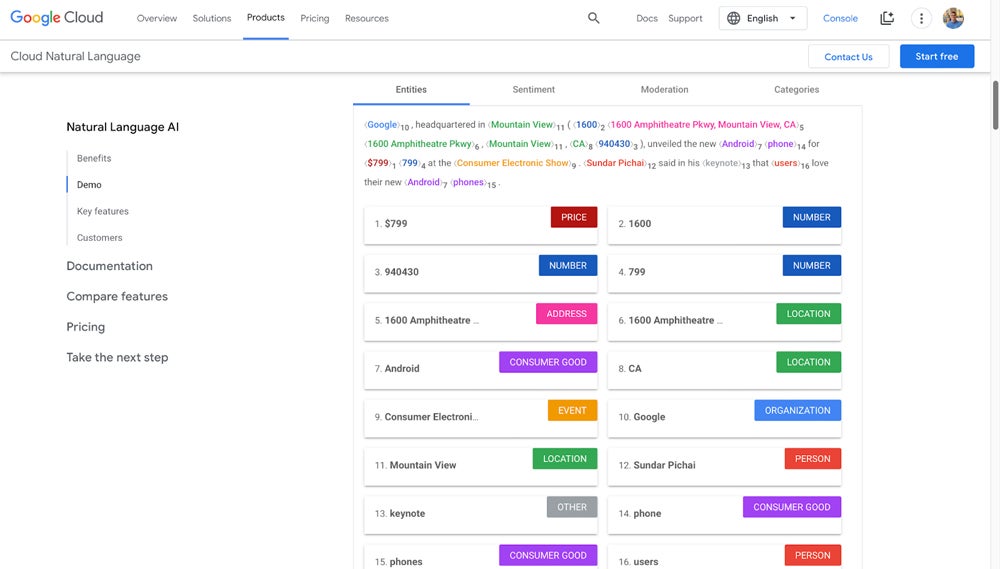
Why We Picked Google Cloud Natural Language API
We chose Google Cloud Natural Language API for its ability to efficiently extract insights from large volumes of text data. Its integration with Google Cloud services and support for custom machine learning models make it suitable for businesses needing scalable, multilingual text analysis, though costs can add up quickly for high-volume tasks.
Pros and Cons
| Pros | Cons |
|---|---|
| Multilingual support | Initial learning curve |
| Classify documents in more than 700 predefined categories | Can be expensive for organizations with lots of data |
| Integrates with other Google Cloud services | Limited customization for specific domain requirements without using AutoML |
Pricing
- Monthly prices per 1,000-character unit vary by amount and feature
- See Google Natural Cloud pricing chart for more information
Features
- Identifies entities and their sentiment within the text
- Allows custom text classification using AutoML for domain-specific needs
- Analyzes grammatical structure, extracting tokens, sentences, and syntax details
- Provides real-time insights from unstructured medical text through Healthcare Natural Language API
How to Choose the Best Natural Language Processing Software for Your Business
When shopping for natural language processing tools, consider the specific tasks you want to accomplish, the complexity of the language data you are working with, the accuracy and performance required, and your budget and technical expertise. You should also consider your future plans for using AI: you’ll need an NLP solution that not only handles current needs, but scales easily with time.
Key technical features to consider before making a decision include:
- Natural language understanding
- Text processing and analysis
- Machine learning and deep learning techniques
- Multilingual support
- Scalability and performance
- Integration and APIs
- Accuracy and reliability
Frequently Asked Questions (FAQs)
Natural language processing tools use algorithms and linguistic rules to analyze and interpret human language. NLP tools can extract meanings, sentiments, and patterns from text data and can be used for language translation, chatbots, and text summarization tasks.
NLP is a core feature of modern AI models. Applications include sentiment analysis, information retrieval, speech recognition, chatbots, machine translation, text classification, and text summarization.
There’s no singular best NLP software, as the effectiveness of a tool can vary depending on the specific use case and requirements. Our review captured the best tools for different users and use cases. Generally speaking, an enterprise business user will need a far more robust NLP solution than an academic researcher.
Yes and no. ChatGPT is built on natural language processing techniques and uses deep learning to understand and generate human-like text. This allows it to engage in conversations and handle various language tasks. However, its main purpose is content generation, rather than traditional NLP tasks like sentiment analysis or named entity recognition.
NLP makes it easier to automate repetitive tasks, like sorting customer support emails or analyzing feedback. It can quickly scan large amounts of text data to find key insights, helping companies understand customer sentiment or detect trends. NLP also powers virtual assistants like Siri and Alexa, allowing for more natural conversations between humans and computers.
Bottom Line: Natural Language Processing Software Drives AI
In recent years, NLP has become a core part of modern AI, machine learning, and other business applications. Even existing legacy apps are integrating NLP capabilities into their workflows. Incorporating the best NLP software into your workflows will help you maximize several NLP capabilities, including automation, data extraction, and sentiment analysis.
Investing in the best NLP software can help your business streamline processes, gain insights from unstructured data, and improve customer experiences. Take the time to research and evaluate different options to find the right fit for your organization. Ultimately, the success of your AI strategy will greatly depend on your NLP solution.
Read eWeek’s guide to the top AI companies for a detailed portrait of the AI vendors serving a wide array of business needs.